


This is Part 1 of a three-part series (links at the bottom).
Traditional search engines and databases match based on keywords. These systems are fine when you’re looking for an exact or partial string match but fail when the goal is to find content that’s conceptually similar, not just textually identical.
Vector search bridges this gap by representing content like text, images, or even audio as coordinates in a multidimensional space grouped by likeness, letting us compare meaning instead of exact terms. When paired with tools like vector indexes and Retrieval-Augmented Generation (RAG), this unlocks smarter, faster, and more scalable search systems.
In this post, we’ll explore how vector embeddings work, how to measure similarity, and how RAG (Retrieval‑Augmented Generation) leverages them for smarter search.
Vector Databases
A vector database is a data store designed to keep each piece of unstructured content—text, images, audio, user events—as a high‑dimensional numeric vector and retrieve the items whose vectors are closest to a query vector. Because distance in this space reflects semantic similarity, these systems let you search by meaning (“forgot login credentials”) instead of exact wording or IDs.
This similarity‑first model unlocks capabilities that conventional keyword or relational databases struggle with: grounding large‑language‑model chatbots in private documents (RAG), recommending products or media based on behavior or appearance, and finding visually or sonically similar assets in massive libraries.
The rapid adoption of vector search by cloud providers, open‑source projects, and managed services signals its graduation from niche ML tooling to a standard layer in modern data stacks.
Vector databases bridge this “semantic gap” by storing and retrieving objects (text, image, audio) as vector embeddings.
Embeddings
An embedding is a list of numbers that represents the meaning of a thing in a way a computer can understand—like GPS coordinates in a space where similar ideas are physically closer together.
For example, “reset my password” and “forgot login credentials” might map to nearby points, even though they use different words.
A modern embedding model (e.g., OpenAI text‑embedding‑3‑small) converts a sentence into a 1,536-dimensional vector. More dimensions mean more nuance but also more storage and compute to compare vectors.
→ car, vehicle, and automobile are close together, while banana is far away.
"car" → [0.2, 0.5, -0.1, 0.8, ...] "vehicle" → [0.3, 0.4, -0.2, 0.7, ...] "automobile"→ [-0.1, 0.6, 0.2, 0.3, ...] "banana" → [-0.1, 0.6, 0.2, 0.3, ...]
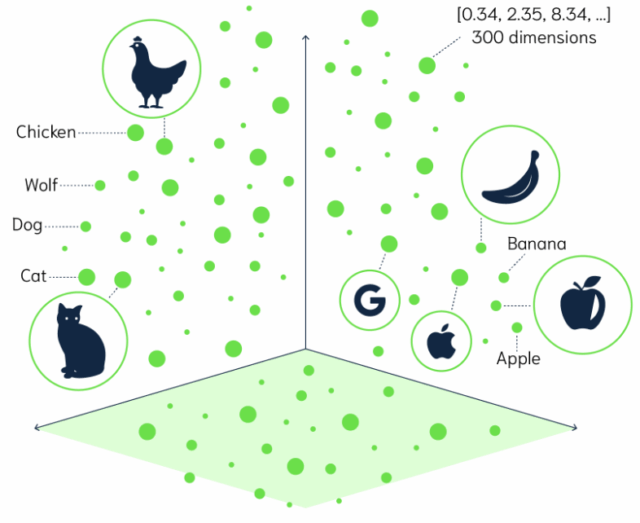
Image Source: OpenDataScience
Measuring Similarity
Choosing the right distance metric determines how “close” two vectors are. The two most common metrics are:
- Cosine Similarity: measures how closely two vectors point in the same direction, ignoring length. Use it when you care about semantic meaning.
- Euclidean Distance: measures the straight-line distance between points. Best for image or pixel-based embeddings.
Vector Indexing
A vector index organizes embeddings into an approximate nearest neighbor (ANN) structure, grouping similar items for faster search.
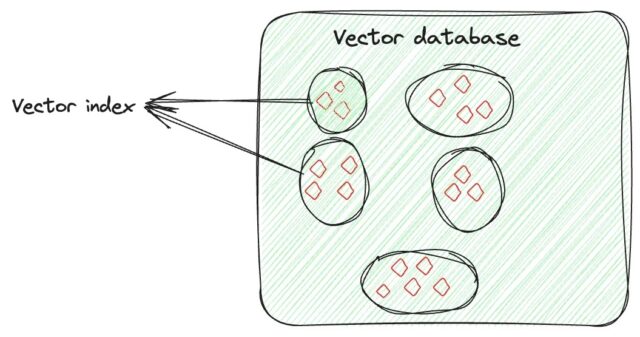
Image Source: Medium
Common vector indexes include:
- HNSW (Hierarchical Navigable Small World): a multi-layer graph that hops toward closer vectors for high performance and low latency.
- IVF (Inverted File): buckets vectors and checks only likely buckets during search, efficient for large datasets.
- MSTG (Multi-Scale Tree Graph): builds multiple levels of smaller clusters, combining tree and graph benefits for memory efficiency.
Retrieval-Augmented Generation (RAG)
Traditional language models generate answers based only on training data, which can be outdated. RAG combines language generation with live data retrieval. The system searches a knowledge base and uses that content to produce more accurate, context-grounded responses, reducing hallucinations and allowing instant updates without fine-tuning.

Image Source: Snorkel AI
Conclusion
We’ve explored the core building blocks of semantic search: vector embeddings, similarity metrics, vector indexes, and RAG. These concepts move us beyond keyword search into meaning-based retrieval. In Part 2, we’ll build a RAG foundation using Postgres, pgVector, and TypeScript scripts for embedding, chunking, and querying data.
References
- Part 2: Coming soon
- Part 3: Coming soon
- Repo: https://github.com/aberhamm/rag-chatbot-demo
Source: Read MoreÂ
